
If you have written external data transfer functionality for ERP software for your enterprise, then you have definitely come across built-in utilities which enable you to create data files that can be sent out to benefit providers, state governments, and anyone else who may need to process data related to employees in your organization. These utilities are a very nifty feature that makes such data transfers a comparably smooth and straightforward process.
But what if you or a non-technical person wants to review the data? While most of this data is usually text, it is often not written in an easy-to-process format, like a CSV file or a tab-delimited file. And, while it is possible to examine these files directly in a text editor like BBEdit or Notepad++, having to track space-delimited fields with different kinds of data bunched up next to each other can be confusing. With that in mind, in today’s Python programming tutorial, we will look at how to extract text from difficult file formats using Python code.
Reading: 6 Best Python IDEs and Code Editors
What is text scraping?
Text scraping is the process of using a program or script to read data from any data stream, such as a file, and then representing that data in a structured format that can be more easily managed or processed. This is typically accomplished by way of regular expressions (Regex) and filtering tools such as grep. However, programming languages like c#, pythonand PHP include robust string processing libraries which make this process much easier for someone who may not be fluent in regular expressions, or who does not want to invest the time needed to become fluent in them.
This article uses Python 3 for the code samples and presumes that you, as the reader, have a basic working knowledge of Python, but these techniques can be done in most other programming languages as well. Before you begin, you may want to read our article Overview of Regular Expressions and Regex in Python.
Parsing Data in Python
Effective text scraping means knowing where, inside the data stream, the information that you are looking for exists. If the data source is the HTML code of a web page, you would need to be able to readily identify that within its source code. If the data source is a file that uses multiple lines for a single data record, then you would need to know the starting and ending points of the information you need. There is no one fixed mechanism for figuring this out. You will need to look at the file to see what, if any, patterns exist in the data.
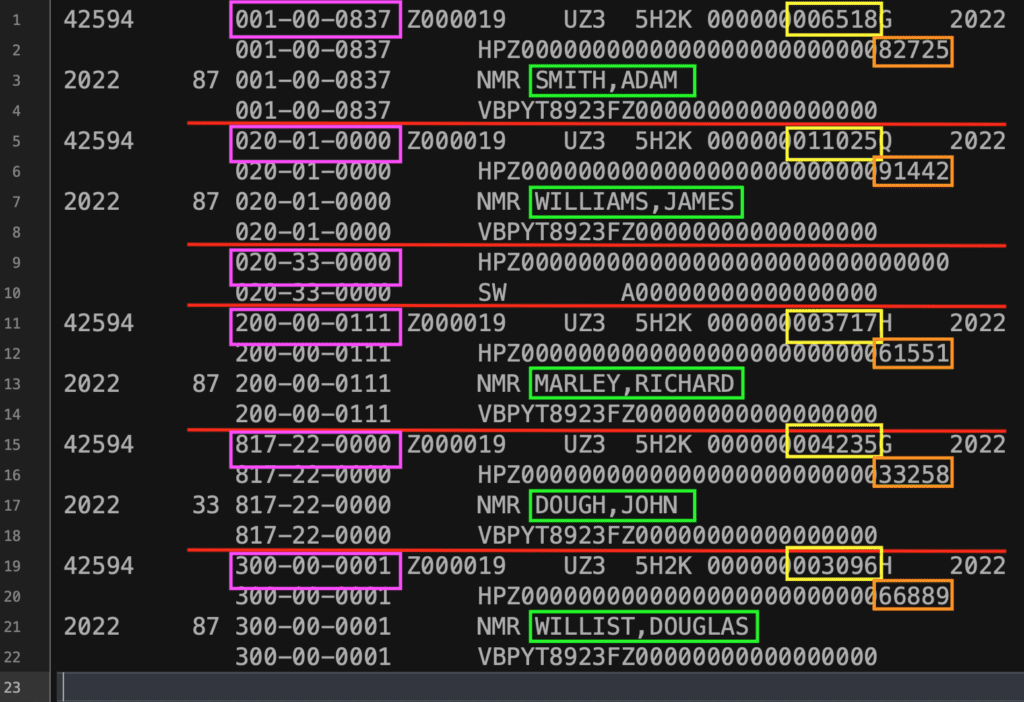
For example, say your source data had the sample contents below, and this information represented health insurance payment information for each employee who elected to have health insurance:
Note: It is very common for text editors that are bundled with Windows or Mac OSX, such as Notepad or TextEdit, respectively, to use proportional fonts by default. This results in increased difficulty in trying to figure out a file format. Either configure these editors to use a fixed-width font like Courier New, or use editors like Notepad++ for Windows or BBEdit for Mac OSX.
It’s pretty easy to parse out things like first names, last names, and Social Security Numbers from this sample data. But say that for the sake of this example, this data could be broken up in the following ways:
Reading: Top Online Courses to Learn Python
It is easy to conclude that a single record of information would be composed of the various data from the items scattered between each of the red lines in the figure above. In this case, a single record would be composed of:
-
- Social Security Number (SSN)
- First Name and Last Name, delimited by a comma
- Two numerical amounts which vary by each employee. In many of the output files that are created by ERP software, this can refer to amounts of money that an employee may be contributing to a retirement plan, or paying for an insurance benefit. For this article, these will be presumed to be:
- A “nonsense” monthly amount, represented by the yellow highlight.
- A “nonsense” yearly amount, represented by the orange highlight.
These files can vary radically in formatting and the kind of information they contain, but if you know how to look at the file, you can definitely pluck out the significant portions that you would want to include in an easier-to-use format. This can include demographic items like:
-
- Phone numbers
- Email addresses
- Dates of Birth
- Home mailing addresses
- Dependent information
- Benefit plan code
If you have access to an employee’s information within the ERP, or if your enterprise permits you to have such access, you can examine an employee’s information to determine which numbers or symbols correspond to the items you may see in an ERP-generated file.
Notice the section of the file with only two lines? That’s not a typo. It will be used to demonstrate how to handle missing data elements, which is a not-too-uncommon problem that seems to crop up when working with data like this.
Keep in mind that you need to have some basic understanding of what the original file represents before you can make design decisions about what data can be plucked out. Given how the sample file is supposed to represent individual employee records, it can be safely assumed that each employee record can be identified by an SSN (in purple) or a name (in green). With those assumptions, records can be delineated where there is a change in SSNs from one line to the next.
As this example is supposed to represent payment information, one could look up further information on each record within the ERP and potentially conclude that the numbers highlighted in yellow may represent the amount of money in a month that the enterprise paid to a health insurer, and the orange number is the total amount.
Granted that I just made up numbers for this example, these numbers are not intended to represent any realistic amount of money.
With that in mind, please also note that, per the US Social Security Administration, any Social Security Number that has 00 in the middle, or 0000 at the end, is invalid. This Python programming tutorial will use such representations of Social Security Numbers for testing purposes.
Reading: A Simple Guide to File Handling in Python
The Goal of Parsing and Extracting Data
As the introduction states, it would be nice to have the values above in an easier-to-use format, such as a CSV file. However, once the pieces of information are plucked out, they can be saved in any kind of structured data file, such as an XML file. However, most end-users who have a need to examine this information would use a tool like Microsoft Excel or the Numbers App that is bundled in Mac OSX to perform such analysis.
For the purposes of this article, the goal is to easily represent the information above in a CSV file that contains lines that follow the format below:
SSN, Last Name, First Name, Monthly Amount, Yearly Amount
Identifying the Data Structure for String Processing Using Python
In order to use string processing tools in almost any programming language, it is important to know where each of the highlighted boxes above begins and how many characters in length the text literal is. Text editors such as Notepad++ for Windows or BBEdit for Mac OSX have built-in functionality which can help you to locate the starting positions and sizes of each literal. Note that both the BBEdit window and Notepad++ window are shrunk for the purposes of this example:

Identifying positions and lengths using BBEdit
The figure below shows how Notepad++ will give the same information, although the selection length does not appear until the text is actually selected:

Identifying positions using Notepad++
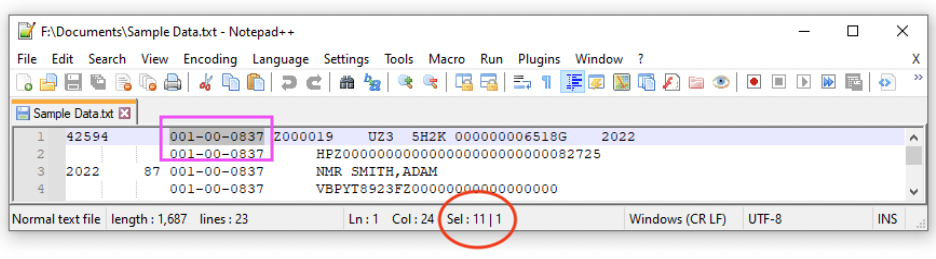
Determining the string literal length using Notepad++
In the example above, the SSN begins at position 13, assuming a 1-index for the character position starting from the left. This can be determined by placing the cursor at the leftmost side of the line, in this case, before the 4 in 42594, and seeing that this position is 1. Moving the cursor to the start of the SSN gets you to character position 13, as shown in the information in the red circle on the left. The mouse or Shift-Arrow can be used to select the whole of the SSN, but not any trailing spaces that precede or follow it. BBEdit then provides the length of the selected text, namely 11 characters, including the hyphens.
An important note: when determining the positions and lengths of string literals, make sure that no spaces or extraneous characters to the left or right of the text is selected, as this will yield incorrect values.
Armed with this information, we can determine that for a given record, SSNs can start at position 13 and extend for 11 characters. Using the same techniques, the same information can be determined for the other items, albeit with some caveats.
|
RecordComponents |
highlight colour |
Starting Position (1-index) |
StringLength |
|
SSN |
Purple |
13 |
11 |
|
Nonsense Monthly Amount |
Yellow |
52 |
6 |
|
Nonsense Yearly Amount |
orange |
58 |
5 |
|
Last name and first name |
Green |
34 |
Varies, but can go to the end of the line. |
Conclusion to Part One of Text Extraction in Python
Now that we have identified the underlying data structure of the text we want to parse and extract, we can move on to the actual Python code we will use to scrape the data from a file. For brevity’s sake, we will cover that code in a follow-up article.
read more Python programming and software development tutorials.